Strategie štíhlé observability: proč tracing nahrazuje technické logování, ale ne business audit
Tradiční monitoring enterprise aplikací dlouho stál hlavně na aplikačních logách. Vývojář do kódu vložil logger.info, logger.debug nebo logger.trace a při incidentu se v textových záznamech hledalo, co se v systému stalo.
V monolitické nebo převážně synchronní aplikaci tento přístup nějakou dobu fungoval.
Exekuce měla relativně přímočarý průběh: request přišel do aplikace, prošel několika metodami, zapsal data do databáze a skončil odpovědí. Textový log se dal číst téměř jako příběh.
V distribuovaných systémech to ale přestává stačit. Mikroservisy, CQRS, event-driven architektury, asynchronní zpracování a paralelní event procesory rozbíjejí jednoduchou představu jednoho lineárního toku. Jeden business požadavek může spustit několik služeb, command handlerů, event handlerů, projekcí, integrací a retry mechanismů. Výsledkem je, že tradiční logy často generují velký objem technického šumu, ale při analýze incidentu neposkytují dostatečný kontext.
Proto dává smysl rozlišit dvě věci, které se často nesprávně míchají dohromady:
- Technické trasování exekuce
Slouží k pochopení toho, kudy request nebo zpráva prošla, jak dlouho jednotlivé kroky trvaly a kde vznikla chyba. - Business logování a audit
Slouží k zachycení významných business rozhodnutí, stavových změn a událostí, které mají doménový význam.
Cílem štíhlé observability není přestat logovat. Cílem je nelogovat technické detaily, které umí lépe zachytit tracing, a naopak logovat pečlivěji to, co má skutečný význam pro business, audit nebo podporu provozu.
Technické logování není tracing
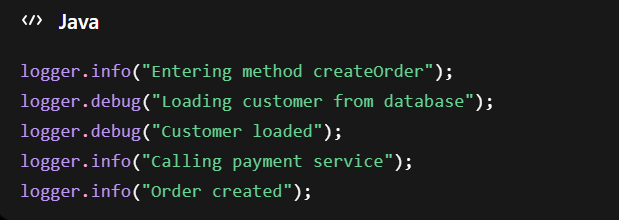
Typický anti-pattern v legacy aplikacích vypadá takto:
Distributed tracing pracuje s pojmy:
- trace – celý tok jedné operace napříč systémem,
- span – jeden krok v rámci trace, například HTTP volání, databázový dotaz, zpracování commandu nebo event handler,
- trace ID – identifikátor celého toku,
- span ID – identifikátor konkrétního kroku,
- attributes – strukturovaná metadata připojená ke spanu.
Místo toho, aby vývojář ručně logoval každý technický krok, observability platforma zachytí průběh exekuce jako strom nebo graf spanů.
V nástrojích typu Dynatrace pak lze vidět, která služba volala kterou, kde vznikla latence, kde došlo k chybě a jaké technické atributy byly s operací spojeny.
To má zásadní dopad na kvalitu kódu. Aplikační kód nemusí být zaplevelený technickými logovacími větami. Zůstává čitelnější a logování se může soustředit na informace, které nelze jednoduše odvodit z automatické instrumentace.
Synchronní svět je pro tracing jednoduchý
U synchronních HTTP nebo REST volání funguje tracing relativně přímočaře.
Příklad:
APM agent nebo OpenTelemetry instrumentace obvykle automaticky přenese tracing kontext přes HTTP hlavičky. Každá služba si z příchozího requestu přečte trace ID, vytvoří vlastní span a předá kontext dál.
Výsledkem je jedna souvislá trace, ve které je vidět celý tok requestu.
Asynchronní event-driven architektura vytváří tracingovou bariéru
Složitější situace nastává v CQRS a event-driven architekturách.
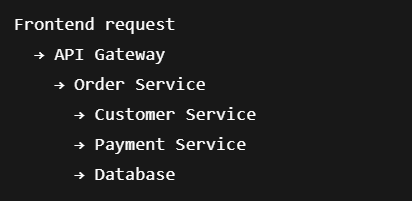
Typický tok může vypadat takto:
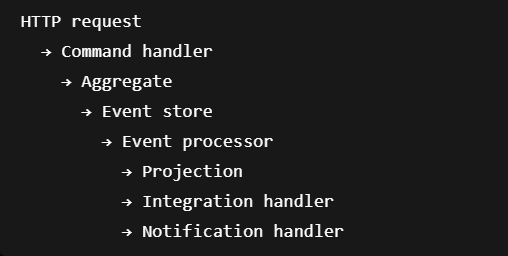
Command vyvolá změnu stavu a uloží event. Tento event je později zpracován jedním nebo více event procesory. Z pohledu runtime už často nejde o stejné vlákno, stejný call stack ani stejný časový okamžik.
Tady automatická instrumentace často nestačí. Pokud se tracing kontext nepřenese explicitně, vzniknou oddělené fragmenty:

Technicky se všechno stalo správně, ale observability ztratila souvislost. Vývojář pak nevidí, že event handler patřil k původnímu commandu.
Řešením je explicitní propagace tracing kontextu přes metadata zprávy.
V event-driven systému by tracing kontext neměl být součástí business payloadu. Patří do technické obálky zprávy nebo do metadat eventu. Typicky se přenáší informace jako:
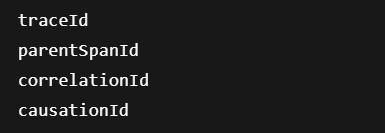
Při zpracování eventu potom event processor tento kontext načte a vytvoří nový span navázaný na původní trace. Díky tomu lze i asynchronní zpracování zobrazit jako související technický tok.
Correlation ID, causation ID a trace ID nejsou totéž
V distribuovaných systémech se často zaměňují tři podobné, ale odlišné pojmy.
Trace ID je technický identifikátor observability. Slouží APM nástrojům k poskládání technického průběhu exekuce.
Correlation ID spojuje více technických operací do jednoho širšího procesu. Například celá objednávka nebo celý onboarding zákazníka může mít jeden correlation ID, i když zahrnuje více requestů, commandů a eventů.
Causation ID říká, která konkrétní zpráva způsobila vznik jiné zprávy. Například command CreateOrder způsobil event OrderCreated.
V ideálním případě používáme všechny tři, ale každé pro jiný účel:

Tím se zabrání tomu, aby se trace ID začalo používat jako business auditní identifikátor, nebo aby se business correlation ID zneužívalo jako náhrada tracingu.
Role aplikačních logů se mění
Pokud tracing převezme technické sledování exekuce, aplikační logy nemusí popisovat každý krok programu.
Místo toho by měly zachytávat hlavně významné události, které mají doménový nebo provozní význam.
Dobré kandidáty na aplikační log:

Špatné kandidáty na aplikační log:
Technické kroky patří do tracingu. Business rozhodnutí patří do logu nebo auditu.
Toto rozdělení je důležité i pro práci se senioritou týmu. Automaticky logovat všechno je jednoduché, ale často líné. Rozhodnout, co je opravdu významná business událost, vyžaduje doménové porozumění.
Doporučený model: tři vrstvy observability
Praktický model může vypadat takto:

Tyto vrstvy se nesmí míchat.
Tracing není audit.
Log není databáze.
APM není levný archiv payloadů.
CloudWatch není doménový event store.
S3 není real-time observability nástroj.
Každá vrstva má jiný účel, jinou cenu, jinou latenci a jiný retenční model.
Logovací pipeline v AWS prostředí
V kontejnerizované infrastruktuře je běžný vzor zapisovat aplikační logy na standardní výstup kontejneru:
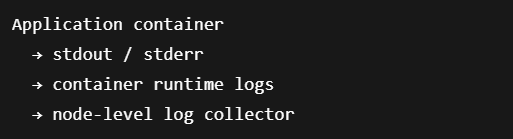
V našem případě logy sbírá Fluentd agent běžící na infrastruktuře. Ten čte logové soubory z EC2 instancí nebo kontejnerového runtime, parsuje je a posílá do dalších systémů.
Zjednodušená pipeline:
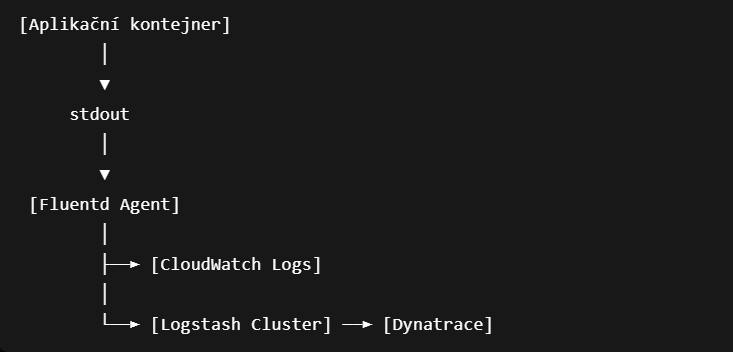
Každý cíl má jinou roli.
CloudWatch Logs slouží jako robustnější technický zdroj logových dat v AWS prostředí. Je vhodný pro incidentní analýzu, dohledání historických záznamů a práci v situacích, kdy real-time APM ingest není kompletní.
Dynatrace slouží jako observability a APM vrstva. Hodnota není pouze v samotných logách, ale hlavně v korelaci mezi logy, traces, metrikami a runtime signály.
Logstash funguje jako mezivrstva pro transformaci, filtrování nebo směrování logů do Dynatrace.
Korelace logů s traces
Aby byla kombinace logů a tracingu užitečná, musí logy obsahovat korelační atributy.
Typický strukturovaný log může obsahovat například:
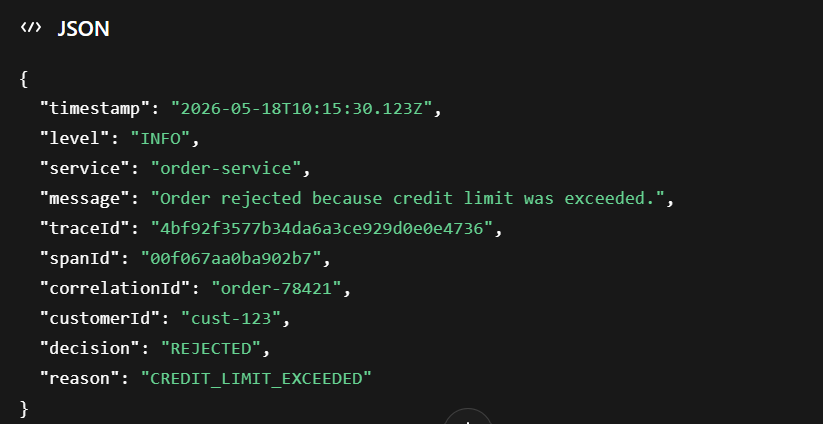
Díky tomu může vývojář v APM nástroji začít u trace, najít konkrétní span a přejít na relevantní logy. Nebo naopak začít u logu a dohledat související technickou trace.
Bez těchto atributů jsou logy a traces dva oddělené světy. S nimi vzniká jeden propojený diagnostický model.
Proč neukládat payloady do logů a trace atributů
Častý požadavek businessu nebo podpory zní: „Uložme celý request a response do logu, ať všechno dohledáme.“
Technicky je to jednoduché. Provozní dopady jsou ale často špatné.
Plné JSON payloady v logách nebo trace atributech znamenají:
- vysoký objem přenesených dat,
- vyšší cenu za ingest a indexaci,
- větší tlak na Fluentd, Logstash a APM backend,
- horší čitelnost logů,
- riziko úniku citlivých údajů,
- složitější retenční a mazací politiku,
- vyšší latenci v horké observability cestě.
Proto je vhodné oddělit technickou observability od auditního ukládání payloadů.
Plné payloady mají být ukládány mimo real-time observability pipeline, například do S3 nebo jiného auditního úložiště. Do logu nebo trace atributu patří pouze reference:
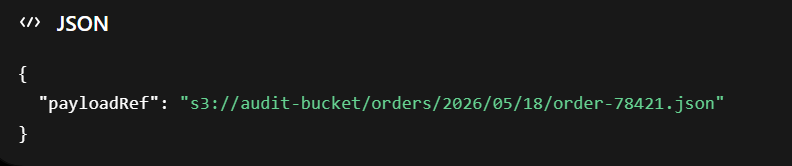
Tím zůstane APM rychlé a levnější, ale auditní informace nezmizí.
DEBUG a TRACE log levely v produkci
V mnoha legacy systémech se DEBUG a TRACE používají jako náhrada za chybějící observability. Výsledkem jsou obrovské objemy dat, které se v běžném provozu nečtou, ale přesto se sbírají, přenášejí a platí.
Ve štíhlém modelu observability by produkční DEBUG a TRACE logy neměly být výchozí diagnostický nástroj. Jejich roli přebírá:
- distributed tracing,
- metriky,
- runtime telemetry,
- strukturované eventy,
- cílená dočasná diagnostika při incidentu.
To neznamená, že debug log nemá nikdy existovat. Znamená to, že nemá být hlavním mechanismem pro pochopení běhu systému v produkci.
Trade-off: fire-and-forget ingest do APM
Real-time doručování logů do APM nástroje má vysokou hodnotu, ale nemělo by ohrozit běh aplikace.
Pokud by výpadek Dynatrace ingestu, Logstash clusteru nebo síťové konektivity zpomalil aplikační requesty, observability by se sama stala zdrojem incidentu. Proto může dávat smysl posílat některé observability streamy do APM režimem fire-and-forget.
To znamená:

Trade-off je zřejmý. Logy v APM mohou být při špičkách nebo výpadcích dočasně nekompletní. Pro kritickou incidentní analýzu proto musí existovat robustnější zdroj, například CloudWatch Logs.
Tento model je přijatelný pouze tehdy, když je jasně komunikováno:

Trade-off: vyšší nároky na návrh
Nejtěžší část tohoto přístupu není technická instrumentace. Nejtěžší je změna myšlení.
Vývojář musí rozlišit:
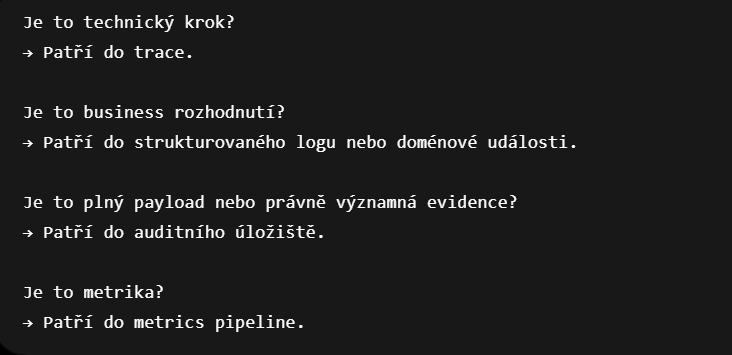
To vyžaduje větší disciplínu než prosté přidání logger.info na každé druhé místo. Z dlouhodobého hlediska ale vzniká systém, který je čitelnější, levnější a lépe diagnostikovatelný.
Praktická pravidla
Dobrá pravidla pro tým mohou být:

Závěr
Štíhlá observability není o tom mít méně informací. Je o tom mít správné informace na správném místě.
Distributed tracing je vhodný nástroj pro technický průběh exekuce. Strukturované logy jsou vhodné pro významná business rozhodnutí. Auditní úložiště je vhodné pro payloady a dlouhodobou evidenci. Metriky jsou vhodné pro trendy, kapacity a alerting.
Když se tyto vrstvy smíchají, vzniká drahý a hlučný systém, ve kterém se incidenty řeší pomalu. Když se oddělí, vzniká platforma, která je provozně čitelnější, finančně udržitelnější a lépe připravená na distribuovanou architekturu.
Nejde tedy o to, že tracing „vytlačuje logování“ úplně. Přesnější formulace je:
Tracing nahrazuje technické logování exekuce.
Business logování a audit zůstávají, ale musí být strukturované, úsporné a jasně
oddělené od APM telemetry.