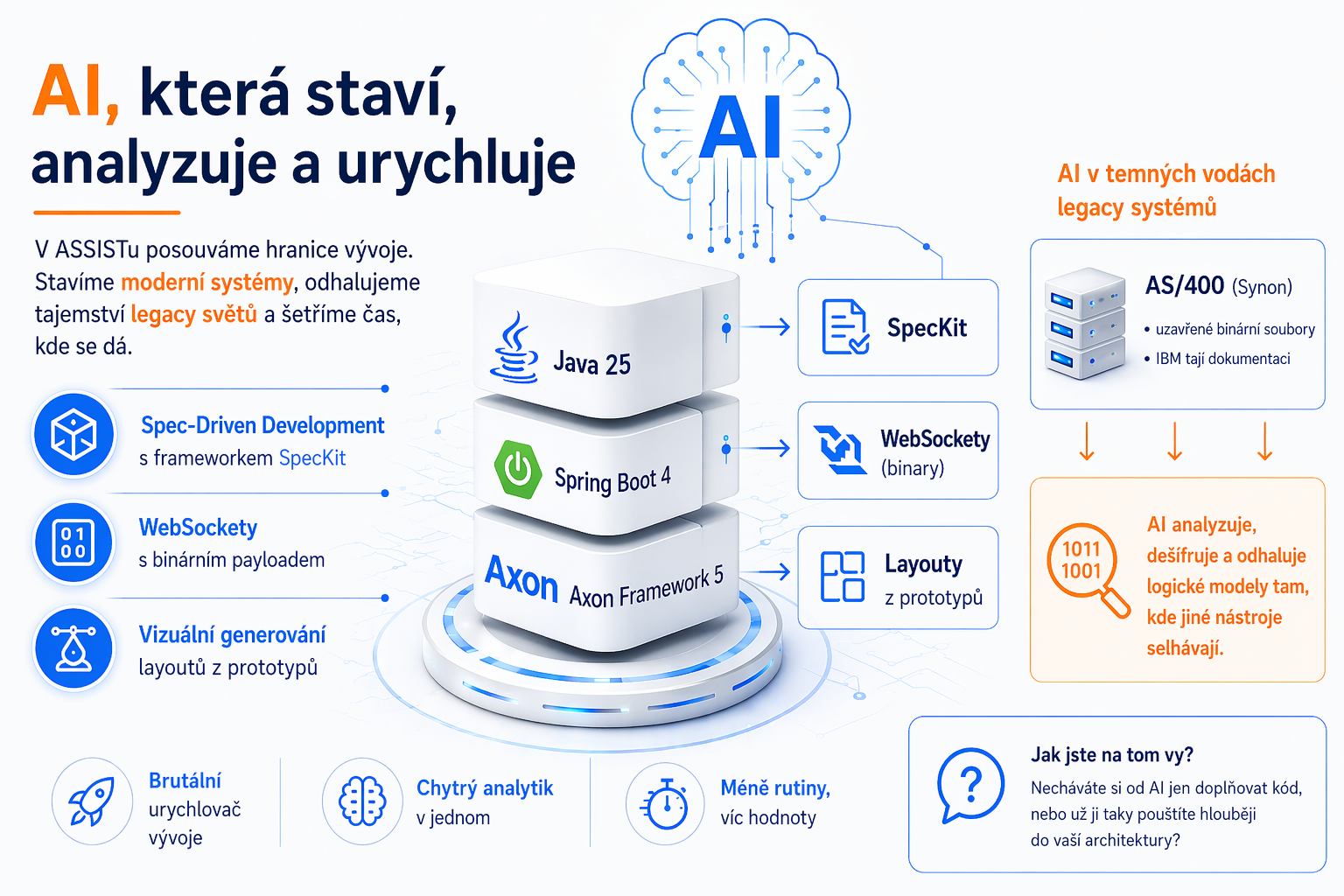
Při práci na rozsáhlých enterprise systémech narážíme na dva extrémy: dynamickou cloudovou infrastrukturu a rigidní legacy systémy bez dokumentace.
Standardní nástroje pro asistované programování (AI) často v těchto scénářích selhávají na omezeném kontextu nebo neznalosti specifických interních standardů. V ASSISTu jsme proto vyvinuli metodiku postavenou na GitHub Copilot Custom Agents a Model Context Protocol (MCP), která nám umožňuje automatizovat interakci s infrastrukturou a provádět hloubkovou analýzu binárních dat.
Deep Dive
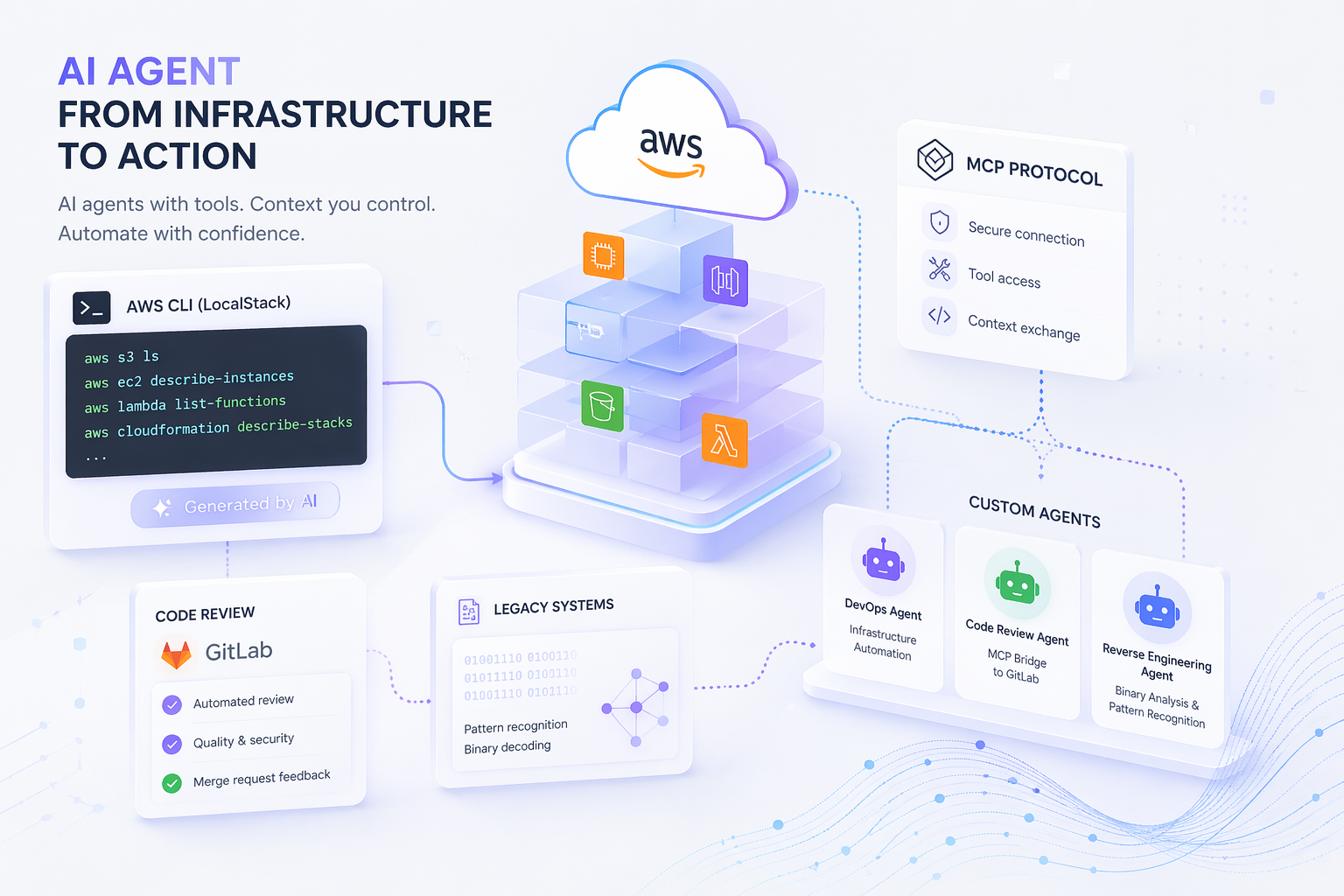
Naše řešení stojí na transformaci AI z pasivního rádce na aktivního agenta. Pro projekty využívající LocalStack jsme vytvořili Custom Agenty, kteří mají přímý vhled do inicializačních skriptů a Terraform definic.
Pokud vývojář potřebuje otestovat SQS frontu nebo nahrát metadata do S3, agent mu nevygeneruje jen obecný kód, ale přesný CLI příkaz odpovídající aktuálnímu nastavení daného prostředí.
Klíčovým prvkem naší architektury je nasazení vlastních MCP (Model Context Protocol) serverů. Tento protokol nám umožňuje bezpečně „vystavit“ naše interní API přímo do rukou LLM. V praxi tak model může autonomně stahovat diffy z merge requestů nebo prohledávat specifické dokumentační repozitáře, aniž by musel vývojář ručně kopírovat tisíce řádků kódu do promptu.
Tímto způsobem efektivně řídíme kontextové okno a předcházíme degradaci kvality odpovědí u dlouhotrvajících sezení.
Extrémním testem této technologie byl reverse engineering legacy systémů (AS/400). S využitím statistických schopností LLM jsme identifikovali strukturní vzorce v hexadecimálních výpisech binárních modelů. AI dokázala odhalit logiku kódování a relace mezi objekty, které nebyly zdokumentovány desítky let. Tento přístup nám umožnil automatizovaně vygenerovat UML akční diagramy a položit základy pro migraci na moderní platformy.
Trade-offs
Nasazení těchto technologií přináší i výzvy. IDE pluginy mají své limity při vykreslování extrémně velkých souborů; například u masivních infrastrukturních plánů musíme data segmentovat, aby nedocházelo k zamrzání rozhraní. Stejně tak je kritické hlídat "čerstvost" sezení – i s pokročilým řízením kontextu má model tendenci po určitém čase fixovat své chyby, což vyžaduje disciplínu v resetování kontextu při změně doménového zaměření úkolu.
LinkedIn